简介:js是浏览器的前端脚本语言
数据类型
1.分类
- 基本类型:String, Number, boolean, undefined, null
- 对象类型:Object, Function, Array
2.判断方法
- typeof: 返回数据类型的字符串表达
- instanceof: 确认具体类型,可以判断其他类型
- === : 可以判断undefined和null类型
3.一些注意事项
- undefined代表未赋值
- null代表为空,一般用于表明将要赋值为对象或者要进入垃圾回收站
变量与内存
1.内存的定义
- 存储在内存中代表特定信息的东西
2.变量与内存的关系
- 如果变量是基本数据,那么a内存保存的是数值,如果是对象保存的便是地址值
- 如果变量存的是变量,则a内存保存的是b的值(不管是数值还是地址)
1 | // 存储地址 |
栈内存和堆内存
- 栈内存:用于存储数值与堆地址
- 堆内存:用于存储对象的属性值
可以说:堆内存是为了存储对象而对栈内存进行的开辟
函数赋值的内存相关问题
如果函数改变属性值,那么函数就会有以下情况:
- 改变基本数据:就会按照期望进行
- 直接对对象属性进行覆盖:会出现undefined
1 | var obj = { age: 15 } |
原理:改变的是栈内存的数据,在函数里面不会释放栈内存,但是会释放堆内存。
因此在函数里面进行对象数据的直接覆盖,当函数一结束,后面会进行垃圾回收,然后将刚赋予的对象全部清除,并回复原样
3.浅拷贝和深拷贝
区别
两个对象A B
A拷贝B
- 浅拷贝:A变化B也变化
- 深拷贝:A变化B不变化
内存变化
- 浅拷贝:A拷贝的是B的栈内存的地址而已
- 深拷贝:A拷贝的是B的堆内存的对象属性值,但是用的是其他的栈内存地址
如何浅拷贝和深拷贝
1 | var a = { |
- 浅拷贝
1 | var b = a |
- 深拷贝:递归拷贝
1 | var deepClone = (obj) => { |
对象属性的添加
用于不确定对象的属性的时候,我们可以用下列方法添加属性
1 | var p = {} |
函数
1.函数的调用
test():直接调用obj.test():通过对象调用new test():new调用test.call(obj):临时让test成为obj的方法进行调用
1 | var obj = {} |
2.回调函数
定义
已经定义了,但是你没有使用,却已经执行的函数
其实有使用,只不过是包装到了一个地方触发了而已
常见的回调函数
- dom事件
- 定时器
- ajax请求
- 生命周期
3.IIFE(Immediately-Invoked Function Expression)
这样子使用,通常不会让自己里面的变量受到污染
- 我们通常使用window.$来对外暴露对象
- $只是一个名字
1 | (function(){ |
函数高级
1.原型与原型链
原型prototype
每一个函数都有一个proptotype属性,指向一个Object空对象(原型对象)
这是用来添加方法用的
原型对象中有一个属性constructor,它指向函数对象
1 | function fun(){ |
显式原型和隐式原型
显式原型:
prototype每个函数都有一个
prototype隐式原型:
__proto__每一个实例对象都有一个
__proto__可以看作是每一次实例化的时候都执行了:
1
this.__proto__ = Fn.prototype
实例化的__proto__就是原来函数的prototype
也就是说,函数的显式原型会作为对象的隐式原型,对象的显式原型会自己重新创建
1 | function FN(){ |
注意:所有函数都是Function的实例(包括Function)
1 | console.log(Function.__proto === Function.prototype) |
构造函数
constructor指向本身构造函数
每一个prototype都有一个constructor,constructor都是指向自身
原型链
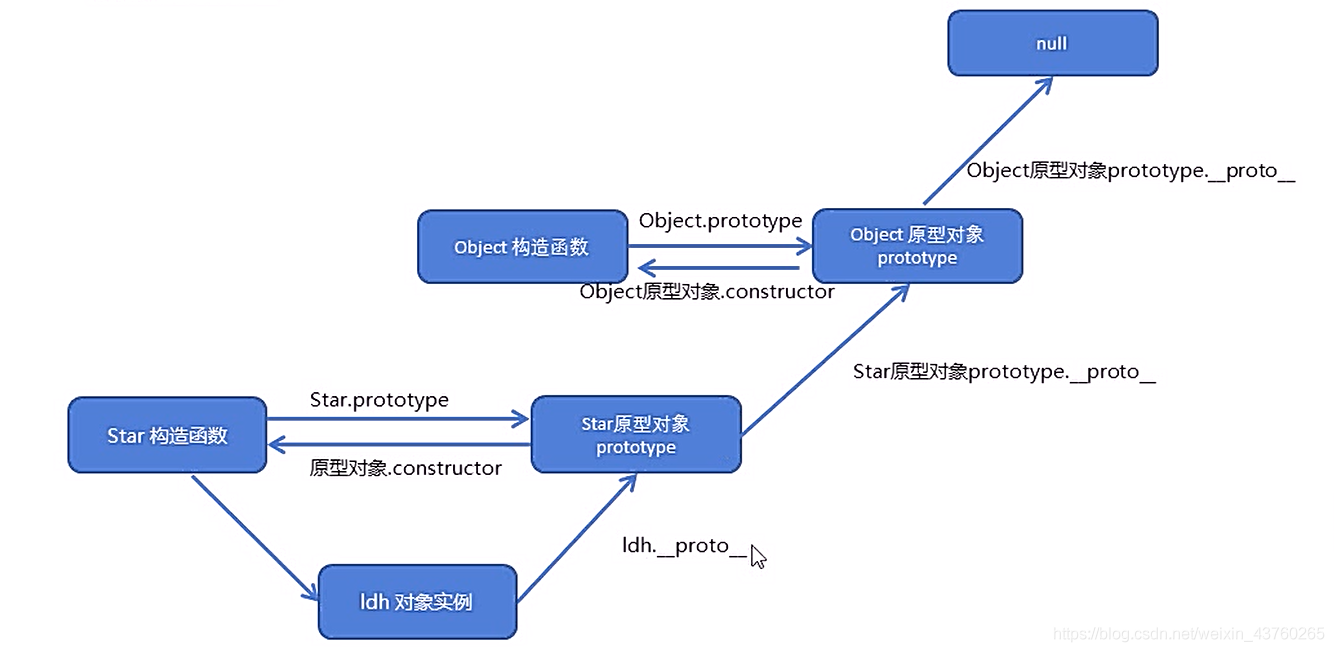
- 那么,你可以将原型对象的prototype指向另一个原型对象的实例,就可以进行原型的链式转换
- 设置对象的属性值的时候,不会查找原型链,会直接覆盖操作
instanceof
A instanceof B:通常用于查看B的显式原型对象是否在A的原型链中,可以理解成:A是B的原型链底层
A顺着prototype找,B顺着__proto__找,如果相遇就判断正确
2.执行上下文与执行上下文栈
全局执行上下文
执行全局代码前将window确定为全局执行上下文
对全局数据进行预处理
- var定义的全局变量为undefined,添加为windows的属性
- function声明的全局函数赋值为fun,添加为windows的方法
- this赋值为window
开始执行全局代码
函数执行上下文
arguments:伪数组在调用函数,准备执行函数体的时候,创建对应函数执行的上下文对象【虚拟对象】
对局部数据进行预处理
- 形参变量预处理为实参,再作为实行上下文的属性
- arguments预处理为实参列表,添加为执行上下文的属性
- var预处理为undefined,添加为该上下文的属性
- function声明的全局函数赋值为fun,添加为该上下文的方法
- this赋值为调用函数的对象,因此可能是windows也可能不是,就是看调用函数的父亲
开始执行函数体代码
执行上下文栈
运行上下文的时候,都是运行栈顶的上下文
- 全局代码执行之前创建一个执行上下文栈
- 全局上下文确定后,将window压栈
- 准备执行函数体的时候,也进行压栈
- 在当前函数执行完成之后,就出栈
- 当所有代码执行完毕之后,只剩下window
一些注意事项
先执行变量提升,再执行函数提升
变量提升也可以提升到
if花括号的外部【因为普通js没有块作用域】
3.作用域与作用域链
作用域
是一个代码段所在的区域
分类
- 全局作用域
- 函数作用域
- 没有块作用域
作用:隔离变量,不同作用域下的同名变量不会有冲突
一般而言,一个上下文对应一个作用域
作用域和上下文的区别与联系:
第一个区别:
- 对于函数,上下文是函数调用时创建,而作用域是函数定义时创建
- 对于全局,上下文是全局作用域确定之后才被创建,全局作用域是无需自己创建的
第二个区别
- 作用域是静态的,只要函数定义好了,就会一直存在,并且不会再变化
- 上下文环境是动态的,调用函数的时候创建,函数调用结束的时候,上下文环境就会自动被释放
联系
- 上下文环境是从属于现在的作用域
- 全局上下文环境对应全局作用域,函数上下文环境对应着对应的函数作用域
作用域链
嵌套的作用域的访问过程
注意:
函数作为参数的时候,我们要看该函数的定义的地方,再来进行作用域链的判断
函数作为对象的方法的时候,如果没有添加this,则在作用域链的上一级来进行查找
1
2
3
4
5
6
7
8
9
10
11
12
13
14var obj = {
fn2 : function(){
console.log(fn2)
}
}
obj.fn2()//报错
var obj = {
fn2: function(){
console.log(this.fn2)
}
}
obj.fn2()//不报错
with语句:主要用来临时扩展作用域链,将语句中的对象添加到作用域的头部
也就是说,使用with可以从外面访问到里面的作用域的变量、函数或者值
1 | var obj = { |
4.闭包(closure)
例子:
1 | <html> |
第一个写法:
1 | // 我们想有一个效果,就是你按不同的按钮就会打印不同的值 |
第二个写法:使用index进行关联
1 | var btns = getElementByTagName('button') |
第三种写法:立即执行函数
更偏向于闭包
1 | var btns = getElementByTagName('button') |
- 闭包的产生:当一个嵌套内部的函数或变量引用了嵌套外部的函数或者变量的时候就会产生闭包
- 闭包的产生条件:函数嵌套并且内部函数引用了外部函数的数据
常见的闭包
将函数作为另一个函数的返回值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65function fn1(){
var a = 2
function fn2(){
a++
console.log(a)
}
return fn2
}
var f = fn1()
f()// 输出:3
f()// 输出:4
// 在这里就是对同一地址的对应变量进行操作
- 将函数作为实参给另一个函数调用
- 总结:闭包找到的是同一地址中父级函数对应变量最终的值
### 闭包的作用
- 使用函数内部的变量在函数执行完之后,仍然存活在内存中
- 让函数外部可以操作函数内部的数据
### 闭包的生命周期
产生:在嵌套内部函数**定义执行完成**的时候就产生了(注意,因为函数提升,所以往往在里面都会立刻定义)
死亡:在嵌套的内部函数对象成为垃圾对象时(或者包含闭包的函数对象变成垃圾对象)
### 闭包的应用
自定义js模块
### 闭包的缺点
- 缺点
- 函数执行完之后如果函数内的局部变量没有释放就会大大占用内存
- 容易造成内存泄露
- 解决方法
- 及时释放内存
- 少用闭包
下面的就是没有及时释放的例子,导致arr一直存在
```js
function fn1(){
var arr = new Array[10000]
function fn2(){
console.log(arr.length)
}
return fn2
}
var f = fn1()
f()
// f = null最好加上,能更好的管理空间
- 内存溢出
- 程序运行出现的错误
- 当程序运行需要的内存超过了剩余内存,就会有该错误
- 内存泄漏
- 占用的内存没有及时释放导致的
- 内存泄漏多了很容易导致内存溢出
- 常见的内存泄露
- 以外的全局变量
- 没有及时清理计时器或者回调函数
- 闭包没有delete